groovyFEWS - Pragmatic Scripting of FEWS configurations with Groovy
Posted: 4 November 2013 by Joel Rahman
I’ve really enjoyed working with Delft-FEWS over the past 12 months or so, but it didn’t take long before I sought out an alternative to building the configuration in XML. That search led me to the Groovy language, which I’d not used before.
Don’t get me wrong, the XML configuration system for FEWS is incredibly flexible and on the whole its very well documented. Once you’re comfortable with editing XML (either in a text editor or a suitable GUI editor), you can build a sophisticated operational system, tailored to your needs. You will build a lot of XML configuration, and there is some complexity there, with a lot of inter-relationships between different configuration files. That said, once you’ve got the concepts in place, you can advance quite quickly.
The two main shortcomings that I saw were that (1) some aspects of the configuration seemed very tedious to develop in XML (whether by hand or with a GUI) and (2) there were various forms of duplication in the configuration, which is bad for maintainability. My FEWS XML configuration files didn’t obey the DRY principle – Don’t Repeat Yourself – and I wanted to fix that.
I was after a solution that would let me develop the configuration with the repetitive and tedious aspects automated. At the same time, I wanted the solution to be a natural fit for the way FEWS is configured. Put another way, I didn’t want my whizz-bang automation approach to complicate the development of the bulk of the system, where there isn’t much in the way of duplication.
After planting the issue in my subconscious, I was rewarded with a recollection of Neal Ford’s excellent book, The Productive Programmer. Among many other pearls, Ford’s book first exposed me to the XML authoring capabilities in dynamic languages, such as Ruby and Groovy.
In the end, Groovy ticked all the boxes and it’s now my preferred way to author FEWS configurations. I’ve released a simple tool for working with FEWS in Groovy. The tool is designed to be easy to pick up and use with an existing, XML based, configuration. Used well, it can make your FEWS configuration much more adaptable and easy to extend.
FEWS Configurations
A FEWS configuration is built through a series of XML files, covering almost every aspect of system behaviour. This includes system configuration (such as user interface, permissions), regional configuration (including locations and groupings of locations, parameters of interest and time-steps used) and workflow configuration (including data import, data export, processing, forecasts and reporting).
A FEWS installation quickly grows to include many individual configuration files, covering different aspects of the system. As a point of reference, a relatively small FEWS that I built had 80 configuration files and a total of around 16K lines of XML configuration1. Another FEWS that I contributed to had over 250 configuration files.
When you’re new to FEWS, it’s easy to become overwhelmed by the scale and complexity of the configuration. All in all, building a FEWS configuration has some similarities with building software and working with a FEWS configuration is somewhat like working with a moderate sized codebase. I like to think that my software development background made the transition to FEWS simpler, but it also made me miss the features of a high level language: principally, I found I was repeating myself way too often.
DRY
The DRY principle, or “Don’t Repeat Yourself”, suggests that a single piece of information should have a single home, from which it can be referenced in multiple places.
Why is it important to be DRY? Because Duplication is bad.
Duplication is bad because it means that, when one thing changes, corresponding changes have to be made in multiple places. It’s easy to forget to make these flow on changes, or to make a mistake in doing so. By following DRY, you look for ways to reduce duplication, to give each piece of information a single home and, as a consequence, to make your system more maintainable.
In some circumstances, duplicating things is the path of least resistance: at least upfront. Copy and Paste makes it easy to reuse the same content in two locations. This is certainly the case with FEWS where you often want the same information (for example, the same colour scheme) in multiple places (for example, on both the interactive maps and in the published reports). This leads to more XML to maintain and more chance of missing something when multiple parts of the configuration need to change in lockstep.
DRY (and not so DRY) Configurations
FEWS itself has facilities for keeping some parts of the configuration DRY. For example, the LocationSets functionality allows the same set of locations (possibly loaded from shapefiles) to be sliced and diced into different groups based on attributes. When the shapefiles change, the LocationSets all change accordingly and this change is propagated to all parts of the system where the LocationSet is referenced.
The FEWS configuration is geared towards simplifying and DRYing the most obvious cases, such as the LocationSets, but there are many other cases where duplication comes in. Three main areas bugged me (there may be more):
- Applying the same basic configuration to different areas, such as different subcatchments,
- Applying consistent presentation settings to different data, such as using the same colour scheme for different spatial rainfall coverages, and
- Expressing consistent TimeSeriesSet queries in multiple places.
Of these, the first two lead to tedious repetition and the opportunity for aesthetic and functional inconsistencies to creep in as the configuration is evolved. The third issue, related to the TimeSeriesSet queries can lead to inconsistencies that stop your FEWS from functioning.
Lets briefly look at each in turn, starting with the simplest to understand: presentation settings.
Parallel Presentations
A typical FEWS configuration will have multiple spatial displays, including the main map view, a grid display for viewing spatial time series and potentially spatial report generation. Each of these displays can be configured independently, but when they share common elements (such as common base layers or common colour schemes) this information is duplicated in multiple XML files. In as sophisticated FEWS setup, this can lead to many hundreds or even thousands of lines of duplicate XML across various files.
For example, the following configuration of base layers would likely appear in multiple files:
<esriShapeLayer id="CatchmentMap">
<description>Catchment Map</description>
<file>Catchment</file>
<geoDatum>WGS 1984</geoDatum>
<visible>true</visible>
<maxScale>1:10000</maxScale>
<lineColor>goldenrod4</lineColor>
<lineWidth value="2" />
</esriShapeLayer>
<esriShapeLayer id="ModelSubcatchments">
<description>Modelled Subcatchments</description>
<file>subcatchments</file>
<projectionFileAvailable>true</projectionFileAvailable>
<visible>true</visible>
<maxScale>1:10000</maxScale>
<lineColor>black</lineColor>
<lineWidth value="2" />
</esriShapeLayer>
<!-- ... -->
Similarly, the following configuration of aggregation periods (used to dynamically accumulate data for display purposes) could appear in numerous places within a single file:
<movingAccumulationTimeSpan multiplier="3" unit="hour" />
<movingAccumulationTimeSpan multiplier="6" unit="hour" />
<movingAccumulationTimeSpan multiplier="12" unit="hour" />
<movingAccumulationTimeSpan multiplier="24" unit="hour" />
<movingAccumulationTimeSpan multiplier="36" unit="hour" />
<movingAccumulationTimeSpan multiplier="48" unit="hour" />
<!-- ... -->
In both cases, you very often want to change all identical pieces of configuration at the same time. For example, when you add a new base layer to a grid display, you will also want the layer in the main explorer view and possibly also in the exported spatial reports.
Repetitive Regions
Often you want the same functionality implemented across different areas within your FEWS system, such as different sub-catchments. The LocationSets functionality gives you a good way to describe the regions, typically by attributing the source data (such as a Shapefile) with information specifying the region for a particular spatial feature. In this sense, you might efficiently partition your gauges into groups for “Smiths Creek”, “Jones Creek” and “Brown Creek”.
However you end up building duplicate configuration, for each region, in various parts of the FEWS configuration. A good example are the filters, which are used to provide access to data in the Data Viewer tool:
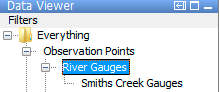
In configuring the filters, you’d build configuration for a Filter (perhaps based on a particular region) containing (1) a named map extent to apply when the user selects that filter, and (2) a list of TimeSeriesSet queries to use to populate the filter with data.
<filter id="Smiths Creek Gauges" name="Smiths Creek Gauges"> <!-- filter for a particular catchment -->
<mapExtentId>Smiths Creek Catchment</mapExtentId> <!-- catchment specific spatial extent -->
<timeSeriesSet>
<moduleInstanceId>ProcessFlowObservations</moduleInstanceId>
<valueType>scalar</valueType>
<parameterId>Q.obs</parameterId>
<locationSetId>Gauges_Q.obs.Smiths</locationSetId> <!-- catchment specific sites -->
<timeSeriesType>external historical</timeSeriesType>
<timeStep unit="minute" multiplier="15" />
<relativeViewPeriod end="0" start="-30" startOverrulable="true" unit="day" />
<readWriteMode>add originals</readWriteMode>
<synchLevel>1</synchLevel>
</timeSeriesSet>
<timeSeriesSet>
<moduleInstanceId>ImportMeasured</moduleInstanceId>
<valueType>scalar</valueType>
<parameterId>P.obs</parameterId>
<locationSetId>Gauges_Q.obs.Smith</locationSetId>
<timeSeriesType>external historical</timeSeriesType>
<timeStep multiplier="15" unit="minute" />
<relativeViewPeriod end="0" start="-30" startOverrulable="true" unit="day" />
<readWriteMode>add originals</readWriteMode>
<synchLevel>1</synchLevel>
</timeSeriesSet>
<!-- ... -->
</filter>
<filter id="Jones Creek Gauges" name="Jones Creek Gauges"> <!-- VERY Similar for next catchment -->
<mapExtentId>Jones Creek Catchment</mapExtentId> -->
<!-- ... -->
Very similar configuration would be built for each region. Often the only change is the value of the LocationSetId element in each TimeSeriesSet query. If you wanted to add a new variable to the region filters, you’d need to add it to each one individually, with a new TimeSeriesSet query.
Eliminating this form of duplication would have a big impact on maintaining and extending a FEWS configuration, making it much easier to add new regions or to consistently modify region specific functionality.
Equivalent Queries
We’ve already seen duplication of very similar TimeSeriesSet configurations. I refer to the TimeSeriesSet elements as queries: In reality they are somewhere between a query and an identifier. The TimeSeriesSet is used to identify a particular chunk of time series from the database, with this identification used to either retrieve that chunk of data, or to store new time series data.
You’ll typically find very similar, but not quite identical, TimeSeriesSet queries in multiple places:
- In the importing of the data, or the generation of the data through a transformation workflow,
- In the application of that data, in one or more places, as inputs either to transformation workflows or forecasts, and
- In the visualisation of that data, possibly in multiple places, such as the time series display, the grid display and/or the reports.
Each use might be slightly different, but share common elements that need to be kept in sync. For example, the data import might store the data with the following TimeSeriesSet:
<timeSeriesSet>
<moduleInstanceId>ImportMeasured</moduleInstanceId>
<valueType>scalar</valueType>
<parameterId>Q.obs</parameterId>
<locationSetId>Gauges_Q.obs</locationSetId>
<timeSeriesType>external historical</timeSeriesType>
<timeStep multiplier="15" unit="minute" />
<readWriteMode>add originals</readWriteMode>
<synchLevel>1</synchLevel>
<expiryTime multiplier="365" unit="day" />
</timeSeriesSet>
While a transformation workflow might work with the most recent data matching the query:
<variable>
<variableId>OriginalFlowRecords</variableId>
<timeSeriesSet>
<moduleInstanceId>ImportMeasured</moduleInstanceId>
<valueType>scalar</valueType>
<parameterId>Q.obs</parameterId>
<locationSetId>Gauges_Q.obs</locationSetId>
<timeSeriesType>external historical</timeSeriesType>
<timeStep multiplier="15" unit="minute" />
<relativeViewPeriod start="-10" end="0" startOverrulable="true" unit="day" />
<readWriteMode>add originals</readWriteMode>
<synchLevel>1</synchLevel>
</timeSeriesSet>
</variable>
Here, the only difference is the addition of the relativeViewPeriod to limit the window of time that the transformation operates on.
Various parts of the TimeSeriesSet need to stay consistent across the different uses of the data, or you will break your FEWS system. In my experience these tend to be some of the more frequently changing parts of the configuration, particularly early on, and it’s easy to break things. This is certainly a mistake that I’ve made on numerous occasions, with some resulting frustration when I try to establish why the data I expect isn’t arriving at the right place.
These were the issues motivating me to seek out a better way. FEWS itself needs its XML configuration, and in some cases that means duplicating content, so the solution needed to be about efficiently generating these repetitive bits from a common source.
Scripting to the rescue?
XML itself has a few options for managing large sets of files, through technologies such as XInclude, but my preference was to move away from XML to another form, such as a script, that gives more expressive power and from which I can then generate the XML as required.
Of course, there is always the possibility of making an imperfect, but bearable situation worse by trying to fix something. In moving from XML to a script, I wanted to make sure I was improving the maintainability of the configuration and that I wasn’t introducing big overheads for the maintainer.
The following attributes sum up what I was looking for in a scripting solution:
- Ability to implement a piece of configuration in one place and use it multiple times, either within the same XML file or across multiple files. For example, use the same map configuration in multiple places.
- Ability to also capture parameterised chunks of configuration and use these chunks in slightly different ways throughout the configuration.
- Ability to store unique data in another form (eg a CSV file) and use that to generate similar configurations. For example, have a summary table of region settings and use this to generate things like Filters for each region.
- Structure of scripts should resemble the actual XML as much as possible, and
- Ability to organise the configuration around the same directory structure as a traditional configuration, with the same mix of XML configuration and other files (shapefiles, images, etc).
I expected that the first three criteria would be met by any general purpose programming language, whereas the last two criteria represented the risk that the solution would complicate the simple stuff. In particular, the desire to structure the scripts similarly to the XML would have two main payoffs:
- The FEWS configuration documentation is based on the XML schemas, so the closer the script is to the structure of the XML, the easier it is to follow the documentation and apply the documentation to the configuration, and
- Tracking down errors in the script, based on problems with the generated XML, is easier if the relationship between the script and the XML is easy to follow.
Most languages have good support for building XML, and a number of these allow you to script XML very elegantly indeed. Ruby and Groovy in particular are two dynamic languages that provide Builders for constructing hierarchical data structures, such as XML, directly within the language code. See, for example, the following snippet of Groovy and the resulting XML:
-
This Groovy code:
gridPlot(id:'ACCESSG Forecast') { timeSeriesSet() { moduleInstanceId('ImportACCESSG') valueType('grid') parameterId('P.accessg.forecast') locationId('NWP') timeSeriesType('external forecasting') timeStep(multiplier:'3', unit:'hour') relativeViewPeriod(end:10, start:-10, startOverrulable:'true', endOverrulable:'true', unit:'day') readWriteMode('add originals') synchLevel(6) } movingAccumulationTimeSpan(multiplier:'6', unit:'hour') movingAccumulationTimeSpan(multiplier:'12', unit:'hour') movingAccumulationTimeSpan(multiplier:'24', unit:'hour') movingAccumulationTimeSpan(multiplier:'36', unit:'hour') } -
Generates the following XML:
<gridPlot id="ACCESSA Forecast"> <timeSeriesSet> <moduleInstanceId>ImportACCESSG</moduleInstanceId> <valueType>grid</valueType> <parameterId>P.accessg.forecast</parameterId> <locationId>NWP</locationId> <timeSeriesType>external forecasting</timeSeriesType> <timeStep multiplier="3" unit="hour" /> <relativeViewPeriod end="10" start="-10" startOverrulable="true" endOverrulable="true" unit="day" /> <readWriteMode>add originals</readWriteMode> <synchLevel>6</synchLevel> </timeSeriesSet> <movingAccumulationTimeSpan multiplier="6" unit="hour" /> <movingAccumulationTimeSpan multiplier="12" unit="hour" /> <movingAccumulationTimeSpan multiplier="24" unit="hour" /> <movingAccumulationTimeSpan multiplier="36" unit="hour" /> </gridPlot>
The Groovy code is structurally the same as the XML, with just minor syntactic differences: most of which, in my view, make it more readable! The Groovy code is easy to write, easy to work with in conjunction with the FEWS XML documentation and the generated XML is identical to XML that you might have authored yourself, making it easy to debug when you have an error.
Importantly, groovyFEWS includes an ‘uncompile’ option, which is able to generate this basic Groovy code from an original XML configuration: so if you’ve already got a FEWS system, you can bring it into groovyFEWS quickly.
This is of course just a starting point, but its a good starting point from which we can begin to write Groovy code to eliminate duplication. As a first example, we can use the list syntax in Groovy to refactor the ‘movingAccumulationTimeSpan’ elements:
-
This
movingAccumulationTimeSpan(multiplier:'6', unit:'hour') movingAccumulationTimeSpan(multiplier:'12', unit:'hour') movingAccumulationTimeSpan(multiplier:'24', unit:'hour') movingAccumulationTimeSpan(multiplier:'36', unit:'hour') -
becomes
[6,12,24,36].each { i -> movingAccumulationTimeSpan(multiplier:i, unit:'hour') }
If you’re keeping score, that only saved us one line of code, but I feel the result is more expressive and we are on our way to a cleaner FEWS configuration.
As I hinted above, one of my common mistakes has been having inconsistent timeSeriesSet declarations: for example having a different declaration in a transformation workflow (perhaps producing input to a simulation) compared to the simulation workflow (that needs the output of the transformation). The result is that the wrong data, or no data at all, makes it to the intended module: usually with some frustration on my part. We can avoid this using Groovy scripting by having a common definition of the timeSeriesSet that we can then call from both places. We can get there by refactoring the timeSeriesSet into a method so that we can call as needed:
-
This
gridPlot(id:'ACCESSG Forecast') { timeSeriesSet() { moduleInstanceId('ImportACCESSG') valueType('grid') parameterId('P.accessg.forecast') locationId('NWP') timeSeriesType('external forecasting') timeStep(multiplier:'3', unit:'hour') relativeViewPeriod(end:10, start:-10, startOverrulable:'true', endOverrulable:'true', unit:'day') readWriteMode('add originals') synchLevel(6) } [6,12,24,36].each { i -> movingAccumulationTimeSpan(multiplier:i, unit:'hour') } } -
becomes
gridPlot(id:'ACCESSG Forecast') { __Helpers.accessgForecast(delegate,-10,10) [6,12,24,36].each { i -> movingAccumulationTimeSpan(multiplier:i, unit:'hour') } // In __Helpers.groovy static def accessgForecast(delegate,startTime,endTime) { delegate.timeSeriesSet() { moduleInstanceId('ImportACCESSA') valueType('grid') parameterId('P.accessg.forecast') locationId('NWP') timeSeriesType('external forecasting') timeStep(multiplier:'3', unit:'hour') relativeViewPeriod(end:endTime, start:startTime, startOverrulable:'true', endOverrulable:'true', unit:'day') readWriteMode('add originals') synchLevel(6) } }
Yes. That’s made it longer, but if we want the same data in another context, we can now just call __Helpers.accessgForecast in the other place, possibly with a different time period of interest.
In this example, the delegate parameter provides the context for the helper method to insert the timeSeriesSet element in the appropriate location within the XML document. The startTime and endTime declarations allow callers from different parts of the configuration to describe different time windows of interest.
I’ve found myself refactoring many such timeSeriesSet declarations into helper scripts. As a result of putting the configuration in one place, and assigning a meaningful name (such as precipitationInputToCatchmentModel), I make far fewer mistakes with mismatched configurations and the resulting Groovy configuration files clearly express the intent of the configuration.
The helper method approach can be used for many parts of the configuration. Returning to the spatial display example, my configuration was developing quite a lot of repetition in the description of maps and base layers. Refactoring the Groovy configuration, and introducing helper methods, has halved the size of this part of the configuration, AND I am able to share numerous helper methods with other files in the configuration.
That’s the core of the scripting solution using Groovy. “groovyFEWS” is a simple tool to manage the process.
groovyFEWS
groovyFEWS works from the command line to translate FEWS XML configuration files to Groovy and back to XML. The tool is designed to translate an entire directory structure, containing configuration files in Groovy, along with other related files (eg Shapefiles), into an equivalent directory structure where the Groovy files are translated to XML readable by FEWS.
Commands
If you have an existing FEWS configuration in XML, the easiest way to get started is to invoke groovyFEWS with the uncompile command, which takes an existing FEWS configuration, with XML configuration files and creates a matching directory structure where all the XML files are translated to Groovy. You can then edit the groovy files, to modify the configuration or simply to reduce duplication, and then use the compile command to translate back to the XML understood by FEWS. In both steps, any other files in the directory structure are carried along for the ride: Shapefiles, DBFs, etc simply get copied back and forth. In this way, you can use the uncompile command to create a new ‘point of truth’ for your configuration, which you can then place under version control.
Given the number of small edits you make in the course of developing or maintaining a FEWS configuration, it would be frustrating to have to invoke groovyFEWS compile for each change. To cater for this, groovyFEWS provides an autocompile command, which watches the Groovy source directory for changes, recompiling or copying files as they are created or modified. Simply start the autocompiler at the beginning of a session and then set about editing the source files knowing that your XML configuration will always be consistent with the latest version of the Groovy code.
Helpers and Related Files
For the most part, you build Groovy configurations in much the same way you work with XML: one file at a time. So instead of editing Explorer.xml to configure the main FEWS Explorer, you would instead edit a file named Explorer.groovy in an equivalent directory.
When you want to share configuration content between files, or to externalise parts of the configuration in something like a CSV file, we need a way to access this other content. By convention, groovyFEWS treats any filename starting with __ as a helper of some sort and doesn’t copy or compile this file. Instead, these files can then be used in your Groovy scripts.
In the earlier example, I placed an accessgForecast helper into __Helpers.groovy. To access this helper from another module, we could use any of the following import statements at the top of a configuration file:
import __Helpers // And then call __Helpers.accessgForecast()
// OR
import static __Helpers.* // and then just call accessgForecast()
groovyFEWS will give your script access to any Groovy helper scripts in the current directory, or any of the ancestor directories of the configuration. For example, a configuration file at Config/ModuleConfigFiles/Forecasts/BrownCkForecast.groovy would have access to any helpers in Config, Config/ModuleConfigFiles and Config/ModuleConfigFiles/Forecasts. In this way, you would store the most generic helpers in the Config directory and more specific helpers further down.
You can have other types of files with names starting with __, but you’ll need to load and process these yourselves. For example, you can use the provided loadTable helper to load a tabular CSV file and named map extents:
-
This CSV file
Whole System,120,130,30,35 Brown Ck,122,124,32,35 Smiths Ck,124,128,30,33 Jones Ck,124,130,33,35with this script
table = loadTable("__Extents.csv") table.each{ row -> delegate.extraExtent(id:row[0]) { left(row[1].toDouble()-buffer) right(row[2].toDouble()+buffer) top(row[3].toDouble()+buffer) bottom(row[4].toDouble()-buffer) } } -
compiles to:
<extraExtent id="Whole System"> <left>120</left> <right>130</right> <top>30</top> <bottom>35</bottom> </extraExtent> <extraExtent id="Brown Ck"> ...
I’d certainly like to see groovyFEWS used by other FEWS configuration builders. One of the key benefits of the tool is that it allows configuration to be written independently of the regional context. In this way we can create and share reusable configuration blocks and consequently get new FEWS systems built more quickly.
Summary
With Groovy, I can work quickly in a format that is close to the XML, but with the flexibility to script where necessary. The scripts themselves are easy to write and I find I can build more configuration in a given time than I could using XML. It’s also easy to translate from the XML focussed FEWS documentation to Groovy.
Writing FEWS configurations using Groovy hits a sweet spot for me. Try it out. I think you’ll find big benefits in DRYing out your configuration. And if you do try it, I’d love to hear how you go.
-
Actually, the FEWS in question ended up with 128K lines of XML configuration, but of these, 112K lines was in a single file that was automatically generated. This was to provide detail around the Historical Events functionality and naturally this data was generated by script. The script in question was 37 lines of Groovy. ↩
