Customising eWater Source (Part 3): Introducing Veneer
Posted: 17 September 2014 by Joel Rahman
This is third and final article in a series on Customising eWater Source. The first article looked at the various motivations for customising Source, before exploring plugins and the Source Function Manager. Plugins are the most established customisation option and there is a lot of power available to the plugin developer. However, for many problems the plugin approach is not the best or most efficient option. The Function Manager is the most commonly used customisation option in Source and is well tailored to its niche of implementing custom operating rules and other aspects of behaviour modelling. The second article looked at two very different approaches to scripting Source: (1) using the Source external interface and (2) manipulating the running software components.
Within their respective niches, the Function Manager and the two scripting options present compelling alternatives to developing C# plugins for Source. However none of the alternatives covered previously are ideal for developing custom user interfaces for Source: to date, that has been the purview of plugins. Unfortunately, plugin development can be slow and tedious.
I’ll conclude this article and the series by exploring the respective niches of the various customisation options. When should you use a plugin and when should you use an alternative?
However, first I want to cover one more way to customise Source.
The bulk of this article is devoted to introducing Veneer, a new way to create custom front ends for Source using web technologies. Developing with Veneer is fast and the results can be very impressive.
Veneer 101
Veneer is designed to make the creation of new front ends for Source faster and easier. These front ends can be generic and work with any Source model, but development is fast so that you can justify building bespoke front ends for particular models: such as building custom reports for a given river valley or building a Source-based Decision Support Tool for an important catchment.
While the overall system is called Veneer, I think in terms of the front ends themselves as being veneers: a thin surface layer of fine material, designed to conceal the more technically oriented interface of Source.
Veneer uses web technologies (HTML, Javascript, CSS), but it is designed to work locally on your machine, with a web-browser in the foreground, but with the Source application running live in the background:
The results are pulled directly from Source and displayed in the browser and the browser can be used to make certain changes to the Source model and to trigger new runs.
While the main Veneer system runs with a live copy of Source, its straightforward to develop a veneer that works both on the desktop, coupled to Source, and the traditional web, where the data is captured from earlier runs:
-
-
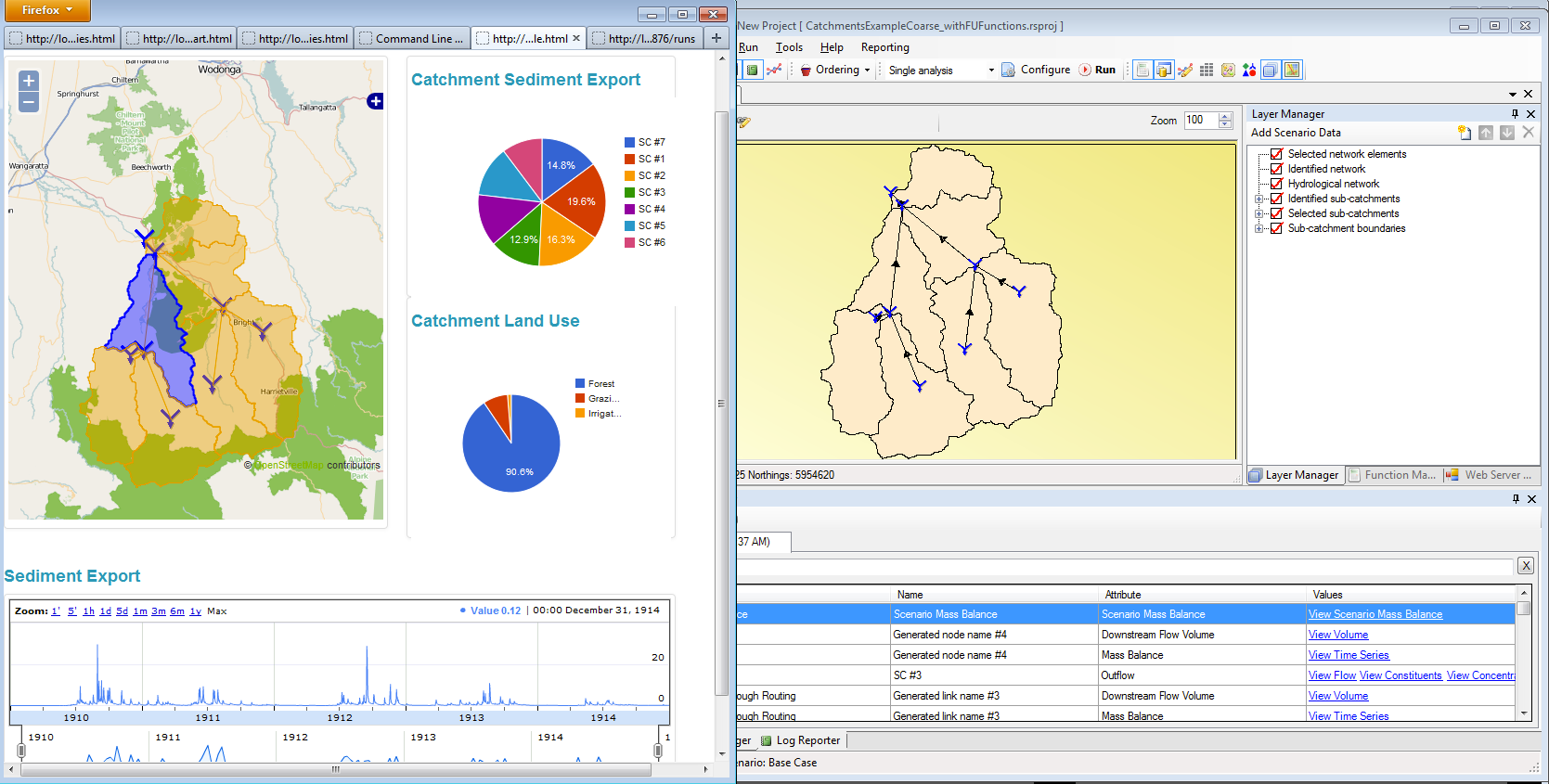
Catchment Sediment Export
Catchment Land Use
-
Sediment Export
Veneer itself runs as a plugin to Source and sets up a local service that makes some of the model data available to be consumed by another program. The other program will typically be a web browser and the data exchange formats have been chosen so as to be easy to consume using Javascript and any one of large number of possibly Javascript visualisation libraries.
There’s three important topics there: (1) Exactly what data is available, (2) How does the other program interact with Source/Veneer and (3) How is the data exchanged. I’ll cover each one in turn.
The Most Important Bits
Veneer provides access to all model results, as well as some contextual information and some parameters.
Veneer is mostly oriented towards providing the results of model runs, and it is possible to access any of the time series results, from any of the runs have been undertaken in current session of the Source application. The full time-series can be requested, but in order to reduce the overheads you can directly access monthly and annually aggregated versions of the data.
The network is available with basic information about the locations of nodes, the connectivity provided by links and, in the case of models with catchment runoff components, the sub-catchment boundaries. The network is provided to help populate visual displays, such as the example used above. The data is provided in the coordinate system used by the Source model, so if the model was built using a well-known projection, it will be possible to overlay the network on other layers, such as the use of Open Street Map in the example.
You can query Veneer for information on Functions in the Source Function Manager1. Where the Function is set to a simple scalar value2, the Function acts as a user defined model parameter. Functions can also be modified by Veneer clients, allowing these user defined parameters to be modified from the custom front end.
In this way, you develop a veneer using Functions as proxies for the parameters that you need to be access. This keeps Veneer queries simple and robust in the face of most changes to the underlying Source software. A consequence is that you tend to create numerous Functions that you wouldn’t otherwise need3. This would be tedious to do manually, but its straightforward to automate. By way of illustration, the land use pie charts in the example above required Functions to be created for the area property of each land use. This was built with a short ironFilings script. The scripting approach is good for the maintainability of the model: The original model (without the extra Functions) can still be used and modified and a ‘Veneer ready’ version (with the extra Functions) can be generated at any time. This is particularly useful when different people are working on the model and the front end: the modeller can modify a clean version and the front end developer can, if necessary, change the script that sets up the functions (to add new functions, for example, for accessing storage characteristics).
In providing access to the results, the network and the functions, the emphasis has been on simple access mechanisms, particularly for web front ends built using Javascript.
RESTful Interaction
On a very small scale, the custom veneer front end and Source (with the Veneer server) form a distributed system. Under the hood, the communication across this distributed system is based on HTTP, with the Veneer server built with an architectural style known as REST, for REpresentational State Transfer. RESTful systems have a number of characteristics:
- Requests identify resources, and sometimes a particular representation (eg HTML, XML). Resources are typically identified using a URI, and this is the case in Veneer,
- Resources are manipulated through their identifiers. When using the HTTP protocol, this means the HTTP GET command4 retrieves a copy of the resource, while PUT is used to provide the server with a newly modified copy of a resource. Importantly, GET shouldn’t modify any server state of consequence5 and a PUT, while it does change server state, should be able to be repeated without having different effect6, and
- Messages are self describing to some extent, such as identifying the file format used for a representation, and
- Connections between resources are implemented as hypermedia. Commonly (and, again, in Veneer) this is through URIs.
Putting this together, writing code (in Javascript or any other language) to interact with Veneer involves:
- Querying one of the base URIs using a HTTP GET in order to retrieve a representations of the data:
/runsfor a list of completed simulations,/networkfor a representation of the network (nodes, links and, if applicable, catchments),/functionsfor the current set of Functions in the functions manager
- Follow the links in those representations to other data of interest. For example
/runsreturns a list of runs, with individual runs represented by another URI7. The data at the individual run URI then contains a list of available result time-series, each with their own URI. - Interpret the individual representations in order to use them in the custom front end.
We can test most of this manually in a web browser. For example, the list of runs available for the earlier example is here:
[
{
"RunName":"Base Case (1 - 6:56:37 AM)",
"RunUrl":"\/runs\/1"
}
]
The listing shows that there is one completed run, which is available at /runs/1 (after removing the escaping characters):
{
"DateRun":"10\/27\/2013 06:56:37",
"Name":"Base Case (2 - 6:56:37 AM)",
"Number":2,
"Results":[
{
"NetworkElement":"Generated link name #1",
"RecordingElement":"Upstream Flow Volume",
"RecordingVariable":"Upstream Flow Volume",
"TimeSeriesName":"Straight-Through Routing: Generated link name #1: Upstream Flow Volume",
"TimeSeriesUrl":"\/runs\/1\/location\/Generated link name 1\/element\/Upstream Flow Volume\/variable\/Upstream Flow Volume"
},
{
"NetworkElement":"Generated link name #1",
"RecordingElement":"Upstream Flow Volume",
"RecordingVariable":"Constituent - TSS",
"TimeSeriesName":"Generated link name #1: Upstream Flow Volume: TSS",
"TimeSeriesUrl":"\/runs\/1\/location\/Generated link name 1\/element\/Upstream Flow Volume\/variable\/Constituent - TSS"
},
{
"NetworkElement":"Generated link name #1",
"RecordingElement":"Downstream Flow Volume",
"RecordingVariable":"Downstream Flow Volume",
"TimeSeriesName":"Straight-Through Routing: Generated link name #1: Downstream Flow Volume",
"TimeSeriesUrl":"\/runs\/1\/location\/Generated link name 1\/element\/Downstream Flow Volume\/variable\/Downstream Flow Volume"
},
. . .
]
}
We can navigate from here to individual result time-series: assuming we first parse the data (easy!).
Meet JSON
Almost all of the data returned from Veneer is in the JSON format, for JavaScript Object Notation. As you might imagine, JSON is very easy to process in JavaScript, but it is also very well supported in most modern environments.
JSON supports objects made of key-value pairs (for example, "RecordingVariable" : "Constituent - TSS"), where the value can be a simple value (for example, numbers, strings, booleans), nested objects (with their own key-value entries) and lists of values (simple values or nested objects).
For the most part, the Veneer JSON representations are very simple and easy to navigate using the links. The network representation (see the example from /network) is a little more complex at first glance, but is still easy to work with because it uses the GeoJSON format, which is directly understood by most web based mapping and visualisation toolkits.
I’ve now covered an example of Veneer and looked under the hood at the data available in Veneer and the mechanisms for getting at and interpreting that data. It’s almost time to turn to the Veneer development model and to look at how Veneer supports rapid customisation of Source. However I want to first cover off on one false impression that you may have at this point.
What Veneer Isn’t
Veneer is not a system for turning Source into a web-based model. Put another way, Veneer is not a way to deploy Source in a Software-As-A-Service approach.
Veneer uses web technologies, principally because web technologies are ubiquitous, powerful and offer very rapid development.
A single running Veneer server works with a single running copy of Source: It is not a multi-user system and this is the main limitation in terms of broader web delivery. That said, you could do a lot, for example, within an organisation, to shift the interface for Source scenario modelling away from the computers used for running the models and to other environments, such as tablets and smart-phones.
There is one area where Veneer is well suited to web delivery, in the traditional sense of public web sites. Veneer can be used to develop canned visualisations and reports, which can be published to the web. These reports can be interactive and dynamic in their presentation, but they remain static in that the results come from an earlier model run8. The Veneer development model provides a smooth transition from interactive use (backed by a running Source model) to publication (with static data). We’ll look at that after we’ve covered the basics of developing with Veneer.
(Very) Fast Development
Development with Veneer is very fast: much faster than building the equivalent front end in a plugin.
Why is it so fast? I think the main reason is because you do the development using a running copy of Source and your model. If all other things were equal, I think this alone would be worth the price of admission. However all other things aren’t equal, and the opportunity to build upon a large suite of Javascript visualisation libraries makes your task even more productive (although choosing a library is a challenge).
Iterate, Iterate, Iterate
Veneer development is characterised by a great many, very short iterations. As the extreme, but still common case, you can make a one-line change to your custom veneer, then refresh the page in your web browser to see the result. All up, the turnaround is a handful of seconds.
If you were developing plugins for Source, it would be difficult to get that turnaround to be less than a minute and the chances are its a few minutes: close Source in order to unlock the DLL for recompilation, recompile, restart Source and get to the point where you can test your plugin. If your plugin is a reporting plugin, you would need to load or generate a scenario and then run a simulation.
With Veneer, Source stays running, your model stays loaded in the application and so do your simulation results. In fact, if you don’t need to modify the model as you development the front end, you can leave Source running indefinitely. I’ve left Source running for days when doing Veneer development.
The difference between a few seconds and a few minutes adds up to a big block of time over the course of just one day. The shorter turnaround also has a positive impact on the way you go about development. The shorter turnaround encourages small changes, which you can assess quickly. The longer turnaround of plugins pushes you towards making fewer, bigger changes and needing to evaluate multiple things each time you run Source to test. It’s easier to get a small change right than a big change. If you happen to make a mistake at step one, you’re much better off if you’re testing and correcting the error after step 1 than if you go on to steps 2, 3 and 4 with the mistake in place, as the plugin development cycle encourages.
The rapid feedback of Veneer development makes learning the system much easier. Make a change, see the impact. Try out a snippet of Javascript from the web, test immediately if it does what you want. Given that Veneer uses standard web technologies, there is a lot of supporting material out there.
Work with Web Technologies
There are three core technologies used for building a custom veneer. You’ve probably heard of them:
- HTML for defining the content and structure of the page,
- Cascading Stylesheets (CSS) for defining style and layout, and
- Javascript for providing dynamic behaviour, including downloading dynamic data, charting and interactivity.
The core of a custom veneer is a web page (or more than one, with navigation links). Because it’s just a web page, you can mix your Veneer elements with regular content (text, images, hyperlinks, videos) and structure (headings, tables, etc).
CSS is used to style all of this regular HTML content, and you can often reuse an organisational standard stylesheet, but also (depending on the visualisation library), CSS is also used to change the appearance of the visualisation elements. As an example, in one of the Veneer samples, the line for the time-series chart is drawn blue, because of the following snippet of CSS:
path{
stroke:blue;
}
This CSS says that any path element on the page, that isn’t otherwise styled through its class or element ID, will be blue.
Using CSS to style your veneers, and using HTML for content and structure, means you don’t need as much Javascript to achieve your desired effect. That said, you will still use Javascript for the bulk of the work in Veneer.
Some version of JavaScript is in every browser in use today, and although browsers have different implementations of the language, there are useful libraries, like jQuery, that iron out the incompatibilities.
Your custom script will usually begin with a call to download one of the JSON data representations from the Veneer server (usually the network, the list of runs, or the information on the latest run). This is done asynchronously, by calling a function that (a) downloads the data at a given URL, (b) parses the data into a JavaScript object and then (c) invokes a callback function that you provide in order to process the data. The callback function modifies the page based on the data, creating new elements to visually or otherwise present the information and often downloading more data (such as particular time-series results).
For example, the following JavaScript uses jQuery to download list of results from the latest model run and add this to a named <div> element on the page:
// Get the list of results from the latest run
// Build a list of the results,
// on the page, in the <div> with id="run_results_list"
// (1) Download the results of the latest run
jQuery.getJSON(v.url("/runs/latest"), function(data) {
// (2) Using jQuery, find the element on the page with id "#run_results_list"
// Remove any existing content (.empty()), then
// Append an empty, unordered list (ul), making the resulting list the 'selection'
list = $("#run_results_list").empty().append("<ul></ul>");
// NOTE Limit list to TEN (10) items for brevity
for(i in data.Results.slice(0,Math.min(10,data.Results.length))) {
// (3) For each row of results (corresponding to a time series)
// append a list item with information about the result -
// where it comes (NetworkElement) from and what its a result for
// (RecordingElement, RecordingVariable)
record = data.Results[i];
list.append("<li>"+record.NetworkElement +": " + record.RecordingElement + " " +
record.RecordingVariable +"</li>");
}
});
Click run to execute the script:
Most Veneer development follows this basic pattern, at least for developing reports and visualisation tools. The details of building particular visualisations depends largely on what visualisation framework you adopt.
Choose a Visualisation Library (if you can!)
Now is a very good time to be creating data visualisations on the web. Good, that is, unless you get overwhelmed by choice. Veneer can be used with any number of visualisation libraries, and you can combine more than one on a single page.
In my work with Veneer to date, I’ve used three main libraries (other than jQuery for basic operations):
- OpenLayers for mapping, including the example on this page. OpenLayers has a lot of power, including the ability to draw in base maps from numerous sources (I’ve used OpenStreetMap here) and to re-project data into common projections. OpenLayers plays well with the GeoJSON data provided by Veneer, but so do a number of other web mapping tools, including LeafletJS,
- Google Charts as one option for displaying basic plots and chart (including the pie charts and time series charts on this page). Google Charts offer a good level functionality out-of-the-box, along with compatibility with older versions of Internet Explorer,
- D3js on the other hand, is fantastic for creating all manner of custom visualisations and animations. With the flexibility comes effort and working with D3js requires more effort than Google Charts. There are emerging add-on libraries aimed at making reusable charts for D3. Another factor with D3js is that it is heavily geared towards the SVG (Scalable Vector Graphics) support, which is only supported by modern web-browsers (eg Chrome, Safari, Firefox and Internet Explorer 9 onwards). If you need to support older browsers, such as IE7/8, then Google Charts is a better option.
It’s worth having a look at the galleries for these and other libraries to get a feel for what is possible. For example, the D3js gallery shows a fantastic range of visualisations.
It’s fair to say that the maps, line charts and pie charts on this page are just scratching the surface of what we can do with Veneer. The beauty of all these examples is that you can easily see how they were accomplished: Use the View Source option in your browser to see the HTML for the current page and navigate from there to the various Javascript and other resources used. And you can create your own with little more than a good text editor.
Tools
If you haven’t worked with web technologies before, you might be surprised to learn that you don’t need much in the way of tools. I currently do all my Veneer related development using just a text editor and a collection of web browsers for testing the results.
For text editing, I use Sublime Text on Windows. There are a number of good text editors. One of the most important features of Sublime Text is the simple notion of a project as a base directory and its subfolders. Building a veneer will typically involve multiple files: one or more HTML files, separate JavaScript and CSS files and, in some cases images and other resources. Sublime Text has tabbed editing for when you want multiple files open at once and there is a a shortcut (Ctrl-P) for navigating to any of the files under your chosen base directory.
TODO: Screenshot
I keep all the files related to the custom veneer in the same directory as the Source project file. Veneer adds all the HTML pages in the current directory to the Reporting menu in Source, allowing the user to launch each into a web browser directly from the main application
TODO Screenshot
Veneer also serves these files over HTTP using the /doc URL prefix9. This makes it easy to distribute a custom veneer with a relevant Source model file, as well as simplifying the task of translating a live veneer to a static veneer for publishing on the wider web.
Web Reporting with Veneer
The discussion so far has focussed on building custom veneers that are used with a running version of Source. This is just one of two natural end-points for a custom veneer. The alternative is to take the veneer (HTML, JavaScript, CSS) and a bottled copy of the JSON data and publish as a static site.
Three aspects of Veneer make this a relatively easy process:
- A provided Python script can be used to download all the data from the Veneer server, storing the data on your local disk in an equivalent directory structure. This means that the relative URLs don’t change much.
- A helper function (in JavaScript) is used to transform the URLs to reflect whether the custom veneer is being used with a running Source or bottled data. Once the data is downloaded and placed somewhere relative to the HTML documents, the differences in the URLs are consistent: The static URLs for data will all end in
.jsonand they may begin with an additional prefix (often, the prefix is.). Thev.url()helper function transforms a URL depending on the current configuration. Every call to download data (egjQuery.getJSON()) should use this helper to first construct the URL. Then its a matter of changing the configuration when deploying the bottled version of the veneer. For example, the main script for this page configures thev.url()helpers with the following prefixes and suffixes:
v.suffix =".json";
v.img_suffix=".png";
v.prefix = "../data/veneer_openlayers_blog_demo";
v.run_substitute = "1"; // Used to substitute for /runs/latest
- Once the data is downloaded (and placed relative to the HTML page and scripts), the whole package is a static website. You can serve a static veneer using any web server on any platform: There is no server side processing at all.
Convinced? I hope I’ve convinced you that Veneer is a powerful and very productive way to develop custom front ends for Source. I intend to produce more Veneer related articles in the future, focussing on particular uses for Veneer that I haven’t the space for here. However there is one more take home message from Veneer.
Veneer Is ONE Option
I began this series by suggesting that plugins weren’t the only way to customise Source and in many cases plugins are not the best choice. Here I’ve introduced Veneer, which is, itself, a plugin for Source: but a plugin that provides a new way to work with Source and reduces the need to write further plugins.
Could we build other Source plugins that themselves provide new alternatives ways to customise the platform? ABSOLUTELY.
In the second article, I looked at using IronRuby or IronPython as a way to script Source at the component level. An obvious plugin would be to embed an IronPython or IronRuby option within the main Source application, so that short scripts can be written and executed from within the GUI. Likewise, another plugin could embed R.NET in the Source application, allowing you to call R data analysis routines directly from the software.
These projects and others can be tackled by anyone who has the interest: The plugin interface to Source provides you all the access you need to build the tools.
Back in the present, you may be left wondering what approach to take for your next Source customisation task. Should you use Veneer? Build a plugin? Write an IronRuby script?
Conclusion: So What Should I Do?
Suddenly there are a lot more choices. Expanding your toolkit beyond the hammer will require effort, but it’s worth it.
I’ve tried to capture my mental decision tree in the following questionnaire:
-
Which Customisation Approach Should I Use?
I hope you have enjoyed and benefited from this series. I’d love to hear how you go with any of the techniques covered here.
-
For more details on the Function Manager, see part 1 of this series. ↩
-
Such as the meta-parameters used by the Source External Interface (see part 2). ↩
-
Although the same approach is used for scripting Source from the external interface. ↩
-
The HTTP/GET command is the most commonly used command in HTTP and is the command your browser used to download this page. ↩
-
Although a GET command can modify inconsequential state on the server: State, such as caches, that exists administratively, such as for performance or logging reasons. ↩
-
We say that PUT is idempotent meaning that multiple, identical requests should have the same as result as a single request. ↩
-
The individual runs have URIs like
/runs/1,/runs/2and the special case,/runs/latestwhich always points to the most recently complete the run. However don’t tell anyone I told you these – you don’t need them. The data at/runswill always point to the available runs. ↩ -
However there is nothing to stop you automatically running the model on some regular basis, for example, with changing data, and pushing these results to the web. ↩
-
This is for more than just convenience. Serving the HTML from the same location as the JSON data is a security requirement for having the JavaScript access the JSON. It’s possible to work around this using a technique JSONP, in which the server is asked to return an actual script, with the script embedding the data in a call to a client-defined callback function. This technique is used on the front page of the Flow Matters site in order to pull a list of Open Source projects for GitHub. ↩