Customising eWater Source (Part 2): Scripting Source
Posted: 6 January 2014 by Joel Rahman
This is the second of a three part series of posts on customising Source. The first gave an overview of some of the options and went into detail on two of those options: 1) the traditional approach of building a plugin DLL in C#, and 2) the newer and very popular approach of building ‘Functions’ within Source itself.
Functions provide a great alternative to plugins for implementing bespoke model algorithms, but there are many other customisation situations not covered by Functions. In the first article, I gave my view on various problems with the plugin development model and suggested limiting our use of plugins to a small set of Source customisation problems. For that to work, we need alternatives, and in this post we explore the options provided by scripting environments.
I distinguish between two styles of scripting Source:
- Scripting the Source command line tool, which provides a means to run models, manipulating inputs and parameters and subsequently retrieving results; as opposed to
- Writing scripts, in a .NET scripting environment, that allows direct manipulation of Source models.
Scripting the command line tool (which I call ‘external scripting’) is more broadly understood at this point in time than ‘internal scripting’, which I believe is another very powerful technique to have in your tool belt. I’ll cover both here, with examples, and give pointers for finding out more.
However, first I want to clarify what I mean by ‘scripting’.
Scripting Approach
There are differing interpretations of the term ‘scripting’: some people thinking in terms of the tools used (such as using a scripting language, like Perl), whereas others think in terms of the task, with an emphasis on little tasks, often for automating an otherwise manual process (for example, I built a script to update all the servers).
Here I’m talking about scripting tasks: tasks where each step could be done manually, but where the overall task would be tedious or impractical unless automated. The language environment used for the scripting is very important for your overall productivity. I’ll give examples in three languages (R, Python and Ruby) that are well suited to scripting tasks. Each of these languages is a capable platform for building large, production quality systems, but they each also offer a great environment for quickly developing scripts.
The languages all have a rich set of third party libraries (unrelated to Source) that help to bootstrap your script with basic functionality.
Importantly, each of the three languages offer a good interactive environment, where individual commands can be tested and larger scripts can be developed. I tend to get hooked on a good interactive language environment, such as the IPython Notebook: It’s a great aide in developing software, but also in automating day to day interactions with something like Source.
Lets start to demonstrate these tools and ideas, beginning with the most common way to script Source: The Source External Interface.
The Source External Interface (aka the Command Line)
The RiverSystem.CommandLine.exe program is (as its name suggests) a tool for running Source from the command line in Windows. Importantly, it also has a client-server mode so that model runs can be performed remotely (to enable simple parallel processing), but also so that the server can perform the time consuming project file load once, and use the loaded data for multiple model runs. The remote access is provided as a Web Service, though one that is intended to be used within a secured, organisational network and, by default, with a one-to-one mapping between server and client.
These different ways of use the external interface lead to the following three, basic commands:
rem : Basic standalone usage, runs the first scenario in ExampleProject.rsproj and displays
rem : the results on the console
RiverSystem.CommandLine.exe --project ExampleProject.rsproj
rem : Start the server, at the default address and load ExampleProject.rsproj.
rem : Don't run anything just yet!
RiverSystem.CommandLine.exe --mode Server --project ExampleProject.rsproj
rem : (and then, in another command prompt window)
rem : Connect to a server at the default address and run the project that is loaded.
rem : Display results on the console
RiverSystem.CommandLine.exe --mode Client
It’s this operational flexibility that leads to it being called the Source External Interface, rather than simply the Source command line.
In addition to the two modes of operation, there are four main operations you can perform through the external interface1:
- Set the value of one or more meta-parameters: User defined parameters that have been defined through the Functions Manager, using the
--valueargument. For example:--value $scalingFactor=1.1 - Step the simulation forward (example:
--step 1), - Run the entire simulation (the default in many cases), and
- Retrieve all, or a subset, of the recorded results (example:
--results $someOutputFunctionto only return a subset of results and--output results.csvto specify a destination file for the results).
Scripting the External Interface
Scripting the external interface is a matter of (a) creating a model and one or more set of inputs to use, (b) constructing a series of command lines for invoking the Source external interface and then, usually, (c) having some means to post process the results.
You could use the external interface just to run a model once, using the parameters and inputs that are configured within the software. This can be useful when the input time series are configured with the Reload On Run option and the time series files on disk are updated. A single run is also useful to test an existing model for changed results against a new release of Source. However in most cases, scripting is used when you need to run multiple (often very many) model runs.
To do something useful with multiple runs, the model needs to be configured to be changed between runs, in at least one of the two ways supported by the Source external interface:
- Have one or more input time series that are configured to Reload On Run, so that the time series is loaded from disk before each simulation, allowing the script to change the on disk content and have an effect on the simulation, and/or,
- Have one or more Functions, with the value of the Function changed by the script between simulations (or, possibly, between time steps).
Changing the value of a Function could be performed in Python with a loop like the following:
# Loop over various values for the $scalingFactor function
for val in [0.9,1.0,1.1,1.2,1.3]:
# Construct the command line by concatenating strings
command = "C:\\SOURCE\\RiverSystem.CommandLine.exe --project MyProject.rsproj " +
"--value $scalingFactor="+ str(val) + " --output=output.csv"
# Call the command
os.system(command)
# Read the output.csv file and process the results in some way...
# ...
That’s pretty simple – but not pretty.
My main complaint is that the code mixes up the main logic of the script (running for multiple values of $scalingFactor) with the mechanics of the model runs (in this case using the RiverSystem.CommandLine tool).
This is a pretty common outcome when people are ‘scripting’ and the Python code above could easily be replicated in any number of scripting environments. In many cases its no big deal. However scripting Source is a case where we’re likely to want to run numerous different scripts (different logic) while reusing the same basic mechanics. We may also want to change the mechanics somewhat, for example to use the client server mode and possibly to run multiple simulations in parallel.
For these reasons, it’s worth starting with some helper scripts that implement the mechanical aspects of running Source and provide the building blocks for solving different types of multiple-run problems.
Simplifying Basic Operations
At a minimum, it’s worth having a way to clearly describe the model parameters and then to use this description to trigger a model run. The dynamic typing in languages like Python can really help here, with the ability to build up objects on the fly. For example, using a generic helper, the earlier example could be replaced with
params = Metaparams() # Initialise an object to accept meta-parameter values
for val in [0.9,1.0,1.1,1.2,1.3]:
params.scalingFactor = val # Set the value in the params object
# Pass the project filename and the params object to the running object
# Get back the parsed results
results = run_source("MyProject.rsproj",params)
# Process the (already loaded) results in some way...
# ...
The run_source method now has responsibility for constructing the command line arguments, based on the parameters defined in the params object, then running the model and loading the results. Gone is any requirement for this script to know the command line argument structure, the path to Source executable2 or even where the results will be stored on disk3. Other aspects of the run, such as whether the run happens locally or on a server, can be likewise be handled through configuration options, or through optional parameters to a method like run_source
results = run_source("MyProject.rsproj",params) # Run Locally by default
# OR
results = run_source("MyProject.rsproj",params,run_on_server=True) # Run on Server
Helper functions can also undertake standard processing of model outputs, such as parsing the date column into date objects for the scripting language and selecting out variables of interest from the results. One approach is to initialise a results template before the run, that can be populated by the run_source helper:
template = Results()
template.waterSupplied = [] # Where waterSupplied is a Function in Source model and
# hence available as an output
results = run_source("MyProject.rsproj",params,template)
total_supplied = sum(results.waterSupplied) # waterSupplied is a time series, sum over whole simulation
Putting all this together, a small number of helpers allow you to write short, expressive scripts, that are flexible and maintainable. All while working at a high level and not dealing with command lines or parsing output files.
For example, a batch run to report about supply shortfalls under various demand scenarios (expressed by scaling current demand), might look like the following:
import numpy # Support for high performance arrays including array arithmetic
import csv
params = Metaparams()
template = Results()
template.waterSupplied = []
template.demand = []
demandFactors = [0.9,1.0,1.1,1.2,1.3]
demandLevels = []
suppliedVolumes = []
for val in demandFactors:
params.demandScalingFactor = val
results = run_source("MyProject.rsproj",params,template)
demandLevels.append(sum(results.demand))
suppliedVolumes.append(sum(results.waterSupplied))
Python and R both have environments with built in plotting4, making it a breeze to visualise the results of the batch run:
plot(demandFactors,demandLevels,label='Total Demand')
plot(demandFactors,suppliedVolumes,label='Volume Supplied')
xlabel("Demand (Fraction of current)")
ylabel("Volume (ML)")
legend(loc="lower right")
Giving:
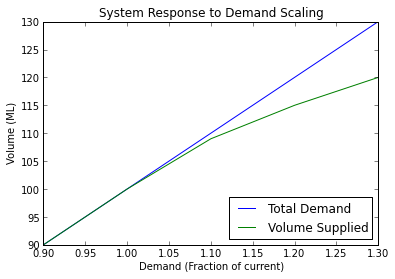
I’ve authored two sets of helper functions for running Source simulations through the external interface: SourceRy, for scripting Source from R and an earlier Python module written for eWater5. At the time of writing, SourceRy is more developed, including support for parallel processing using multiple Source servers and having standard ways to describe various types of scenarios.
Overall, a supportive scripting environment, a small set of helper functions and the Source external interface enables a wide range of simulation problems to be tackled efficiently. This approach won’t work for everything however. In particular, you can’t use the Source external interface for tasks that require making structural modifications to a model, or tasks that need to change parameters that aren’t exposed through the Functions Manager. For these types of problems, you could build a plugin to the main Source application. Alternatively, you could script the internals of Source.
Scripting from the Inside
By internal scripting, I’m referring to scripting environments that can access the components that make up the Source system, rather than just the deliberately limited set of actions available through the external interface. In this sense, the script has the same access as a plugin: the script can query or modify any aspect of the system. This includes loading projects from disk, creating new scenarios and modifying model structures (adding or removing nodes). This is in addition to the types of functions available through the external interface: changing inputs and certain parameters, running the model and retrieving results.
In having the same power as a plugin, the author of an internal script is exposed to the same complexities of the Source software, but the interactive nature of the scripting environment provides a good antidote to this complexity, by offering a way to explore the internals of system, at run time, through trial and error. Indeed, its this ability to learn about Source through exploring, poking and prodding the running system that is one of the main advantages of the internal scripting approach: even if your end goal is to create a traditional plugin.
Internal scripting requires a scripting tool that can access .NET assemblies. Of the various options, I’ve mainly used the Iron languages: IronPython and IronRuby, which offer native .NET implementations of their namesake languages, Python and Ruby. Other possibilities include Windows Powershell, which comes with recent versions of Windows, and rClr, an R package that gives the ability to use .NET classes from within a standard R installation6.
The following Ruby script offers a first, but non-trivial, example of what can be done using internal scripting. This example makes a structural change to a model: setting all links in the model to a particular flow routing routine. Source currently offers three flow routing options: Lagged, Straight Through (ie no delay) and Storage Routing (which can be parameterised to mimic techniques such as Muskingum). The script takes a project file as a command line argument, and changes the routing routing in each link within the first scenario. The script loops through each routing type, saving the project as a new file each time.
# Script to replicate a project using each of the available flow routing types
require 'source_access' # Import a module of helpers from ironFilings (see below)
include RiverSystem
include RiverSystem::Flow
project_fn = ARGV[0] # Project filename given as a command line argument to the script.
project = load_project(project_fn) # Load the project using a helper from ironFilings
basename = project_fn.gsub ".rsproj", "" # Get the name of the project without the .rsproj
scenario = project.get_scenarios[0].scenario # Get the first scenario
network = scenario.network
routing_types = [StraightThroughRouting,
LaggedFlowRoutingWrapper,
StorageRouting]
routing_types.each do |rt|
routing_name = rt.to_s.split("::")[-1]
puts "Setting all links to " + routing_name
# Loop through each link, setting the flow_routing property
network.get_i_links.each do |link|
link.flow_routing = rt.new # (create a new instance of the flow routing model)
end
new_fn = basename + "_" + routing_name + ".rsproj" # Generate a new filename by inserting the routing type
save_project(project,new_fn) # Save the project out using a helper from ironFilings
end
Running this script from the command line results in three new project files in the directory:
C:\temp>"c:\Program Files (x86)\IronRuby 1.1"\bin\ir64 all_routing_options.rb ..\sample_data\YieldExample.rsproj
Using Source from C:\Program Files\eWater\Source 3.4.3.540\
<...log mesages...>
About to load
Setting all links to StraightThroughRouting
SAVING
Setting all links to LaggedFlowRoutingWrapper
SAVING
Setting all links to StorageRouting
SAVING
C:\temp>dir ..\sample_data
<...>
16/10/2013 12:34 PM 732,654 YieldExample.rsproj
25/10/2013 12:33 PM 736,552 YieldExample_LaggedFlowRoutingWrapper.rsproj
25/10/2013 12:33 PM 738,969 YieldExample_StorageRouting.rsproj
25/10/2013 12:33 PM 734,502 YieldExample_StraightThroughRouting.rsproj
If you’ve never used Ruby, or never worked with the internals of Source, then that script could look pretty tricky, so I’ll walk through it in a bit more detail. However, for what it does, this script is pretty concise and, I think, simpler than the alternatives. It’s also quite efficient to develop this type of script. The ability to develop the script interactively, typing in individual commands at (in this case) the IronRuby prompt means you can learn as you go, keep what works and discard what doesn’t.
Lets look at the script piece by piece, starting, perhaps unsurprisingly, with the use of helper functions to simplify aspects of working with Source.
ironFilings
In the same way that helper functions were useful for simplifying the job of scripting to the Source external interface, helpers are a great way to bootstrap internal scripting. In fact, given that the components in Source weren’t written with scripters in mind, a few good helpers to encapsulate common tasks can make an enormous difference.
I’ve just begun to package up useful helpers and example scripts under ironFilings on GitHub. The example Ruby script begins by including the main helper module, source_access which provides for loading and saving Source project files7:
require 'source_access'
# If you need to specify a particular Source version, set the path before calling require
# for example:
ENV["IRON_FILINGS_SOURCE"] = "C:\\Program Files\\eWater\\Source 3.5.0.688"
require 'source_access'
Loading and saving project files is our only use of ironFilings in this script:
project_fn = ARGV[0]
project = load_project(project_fn) # Load the project using a helper from ironFilings
# . . .
new_fn = basename + "_" + routing_name + ".rsproj" # Generate a new filename by inserting the routing type
save_project(project,new_fn)
ironFilings has other helpers, such as create_function_for_parameter, which creates a new Source Function for a parameter of a particular object, enabling that parameter to be subsequently controlled by the external interface (or Veneer, as we’ll see in the third article!). create_function_for_parameter initialises the Function to the current value of parameter, so in the first instance, the model results are unchanged.
Manipulating Source Models
Once the project is loaded, the example script work directly with the Source components: ironFilings isn’t used again until the project files are saved.
For changing the routing model, it was a matter of first obtaining the network for the scenario, then iterating through each link, changing the flow_routing property to a .new instance of our particular flow routing routine:
network.get_i_links.each do |link|
link.flow_routing = rt.new
end
Similar approaches can be used for manipulating other aspects of the model structure, such as changing rainfall runoff models. Certain changes are trickier, because they require changing multiple parts of the system at once and these actions are well suited to creating new helper functions that encapsulate the changes as a single, atomic operation.
While the example script is concise, it wouldn’t be possible without some understanding of the internal structures of Source. Where does that understanding come from?
Finding Things in Source
Interactive environments, like IronRuby, allow you to interrogate a running system to see how it is structured, coupled with a certain amount of trial and error when things aren’t as clear as we’d like.
At its simplest, we can find the available operations on an object, using the methods method (where “»>” is the interactive prompt in IronRuby):
>>> p = load_project('project_file.rsproj')
>>> p.methods
=> ['restriction_curve_sets=', 'restriction_curve_sets', 'scenarios_to_run', 'chart_template', 'chart_template=', 'temporal_data_sources', 'parameters', 'icon_category', 'create_view_table_updater', 'temporal_data_manager_creator', 'temporal_data_manager_creator=', 'construct_new_scenario', 'get_rs_scenarios',
...
That will tell you everything you can call on the p object, but the output is verbose and unfriendly. ironFilings offers a couple of simple helpers for searching for particular operations based on text from the name (nice_methods), and for finding out more information on individual operation (get_info). For example, you could rightly think that the line in the example where we obtained the scenario was unintuitive:
scenario = project.get_scenarios[0].scenario # Get the first scenario
The scenario object contains all the important other objects, such as the network. Here, it’s almost as if we have to ask twice to receive it. We can find our way to the object by querying the running system:
>>> require 'helpers'
>>> nice_methods(p,/scenario/) # Search for any operation with 'scenario' in the name
scenarios_to_run
construct_new_scenario
get_rs_scenarios
remove_scenario
scenario_containers
scenario_containers=
get_scenarios
add_scenario
new_scenario_name
scenario_added
scenario_removed
=> nil
>>> get_info(p,'get_scenarios')
=> [TIME.ScenarioManagement.AbstractScenarioContainer[] GetScenarios()]
From here we can see that get_scenarios will give us an array (the [] notation) of AbstractScenarioContainer objects. Lets get the first one (item [0]) and see where that leads us:
>>> scenario_container = p.get_scenarios[0]
=> RiverSystem.RiverSystemScenarioContainer
>>> nice_methods(scenario_container)
river_system_scenario
river_system_scenario=
...
scenario
scenario=
scenario_description
scenario_description=
...
From the full listing from nice_methods, this doesn’t seem to be the scenario object itself (it doesn’t have anything that’s obviously the ‘network’), but there do seem to be options for getting to the scenario.
>>> scenario = scenario_container.scenario
=> Scenario 1
>>> nice_methods(scenario)
available_date_ranges
...
network
network=
start
Now we seem to have it. We can test a little more to see if we can find some data that we recognise:
>>> scenario.start
=> 1/01/1975 12:00:00 AM
We could confirm that that is indeed the start date for the sample scenario, and we could look at other attributes that tell us we’ve found the right thing. If the system is well documented or you have access to the system source code, the interactive shell is still a welcome addition to your toolset, providing immediate feedback. If your working with a lot less information, the shell’s ability to query and experiment can often get you by. Best of all, the experimenting results in a working script, saving you the trouble of another approach, such as a C# plugin. Provided, that is, that you don’t need a fancy graphical interface.
Do you really need that GUI?
eWater Source has traditionally been a very user-interface focussed tool and when people develop plugins, there is usually an expectation that the end user will work through a Graphical User Interface (GUI) of some kind8. In stark contrast, all of the examples in this article are intended to run either from the interactive shell of the scripting tool, or from the command prompt. There wasn’t a GUI in sight.
There are indeed well supported toolkits for creating GUIs using each of the language environments discussed here, and, depending upon your target users, it can be a worthwhile thing to do. However, in many cases it won’t be worth the effort, and, you’ll be trading away great flexibility (in the interactive shell) for the usability benefits (of the GUI).
Conclusion: The Niche for Scripting Source
In this article, we’ve looked at two styles of scripting:
- External Scripting using the Source external interface to trigger one or more model runs with custom input time series and parameters, and
- Internal Scripting that uses a .NET scripting tool to manipulate the inner workings of a Source model.
So what are scripts good for?
The narrow interface of the Source external interface is well suited to many type of batch simulations, include running numerous scenarios and optimisations. When coupled with helper functions in your scripting language of choice, the external interface is a very efficient way to automate bespoke simulation jobs. The external interface also works well for system integration problems.
The internal scripting approach is very flexible and is a great way to automate a range of changes to existing models. This includes the types of structural changes used in the example script, but also many other model configuration problems, such as automatically assigning parameters based on spatial data sources. Strictly speaking, there is no reason why you couldn’t use internal scripting to undertake the types of scenario runs that work with the external interface, but, where the external approach works, it should be used because it is simpler.
I don’t tend to build Graphical User Interfaces when scripting, but there is no reason why you couldn’t. When it comes to Source and building custom user interfaces, I take the following approach:
- If the functionality doesn’t need to be wrapped in a GUI, then I’d use a script,
- If the functionality needs to be delivered in a custom user interface and it needs to manipulate the model structure, then I’d write a C# plugin, and
- If we need a custom user interface, but the functionality is at the level of changing inputs and parameters, running models and reporting results, then I’d build a Veneer.
Coming up
In the third and final article in this series, I’ll focus on Veneer, a new technology for customising Source, developed by Flow Matters. Veneer lets the you build custom front ends for Source using standard web technologies: HTML, Javascript and Cascading Stylesheets (CSS). Veneer can be used in a number of ways, notably for custom visualisation, standardised reporting and developing highly tailored interfaces.
Veneer is all about rapid development and in the next article I’ll explain why the web technologies used by Veneer speed up the development of custom front ends for Source.
Veneer is just one example of creating a new customisation technology to Source. It’s easy to envisage other ways to customise Source and the openness of the platform means that this functionality could be developed by members of the Source community.
This series is about demonstrating different options for customising Source and recognising that each option is only fit for certain purposes. I’ll conclude the final article by summarising my views on the best approach for various types of Source customisation problems.
Footnotes
-
It is also possible to receive an XML representation of the project file, or some subset of the project, using XQuery. ↩
-
Indeed it’s good to keep the configuration related to RiverSystem.CommandLine.exe separate to facilitate running with different versions of Source. ↩
-
With this approach, your script doesn’t even know that the results get stored on disk. The
run_sourcemethod would typically configure Source to save the results to a temporary file, then load and subsequently delete that file after the run. ↩ -
In the case of Python, plotting isn’t a feature of the standard environment, but the IPython environment has excellent plotting through matplotlib. ↩
-
The Python module was created as part of a tutorial on using Python with Source. The tutorial and source code are available to registered users of the Source community on the community website (logon required). ↩
-
Indeed, the lead developer of rClr is Jean-Michel Perraud: the developer of the popular Rainfall Runoff Library and a big contributor to the development of TIME and Source. ↩
-
Perhaps surprisingly, it’s not that straight-forward to load and save an .rsproj file from code. See relevant code in ironFilings. ↩
-
But not all plugin authors need to create user interfaces. In some cases, Source is able to automatically generate the GUI for a plugin, at runtime, using metadata from the plugin author. ↩