SourceRy - Simple Potions for Complex Source Scenarios From R
Posted: 4 October 2013 by Joel Rahman (Updated: 4 October 2013)
SourceRy is a collection of R modules for managing lots of Source model runs: Setting up the runs, running them in parallel with available computing resources and post-processing the results.
Along the way, SourceRy allows for a powerful recasting of the scenario concept in Source.
Scenarios in Source
Out of the box, Source provides two ways to think about scenarios:
- The official Scenario feature, where a Source project is made up of multiple, independent scenarios, and
- The Input Sets feature, where data inputs and parameters can vary between runs of a single Scenario, according to which of a set of named ‘Input Sets’ is enabled.
These options are good, but not great.
When using the Scenario feature, each scenario in the project is completely independent. The scenarios can have different network structures, parameters, inputs: everything. For some use cases, this flexibility is warranted, but in many cases it is a hassle.
With the independence of scenarios, comes the fact that any similarities are, from the perspective of the software, purely coincidental. This is a problem when, for example, you have a base scenario and would like changes in the base to be reflected in the derived scenarios.
The Input Sets feature is newer, and goes some way towards addressing this issue by allowing a single Source Scenario to have alternate sets of input data and parameters. For example, this might work well for comparing system performance under a ‘Dry’ climate series, an ‘Average’ series and a ‘Wet’ series.
If we think of Input Sets as providing a ‘small-s’ scenario, they have a couple of key benefits over the older, ‘big-S Scenarios’. Using Input Sets:
- any changes to the underlying scenario is automatically reflected in model results for all of the Input Sets - the maintenance of the model configuration is reduced because changes don’t need to be manually propagated to different scenarios, and
- the scenario is redefined as ‘this set of parameters and inputs that matter to this model’, whereas the big-S Scenario is defined as ‘a complete and standalone model configuration with all structure, inputs and parameters’.
This view of scenarios as ‘changes that matter’ can be taken further than the Input Sets feature allows.
Scenarios as Change Sets
Describing a scenario in terms of the ‘things that differ’ makes sense. This is the way scenarios are described in modelling reports. (You wouldn’t write a report that verbosely describes the entire model structure and parameter sets for each scenario if 95% of the information is the same across all scenarios.) Since we think and talk about scenarios in terms of differences, it make sense to represent them this way in the software.
This approach also opens up a range of patterns for constructing and combining scenarios, such as:
- Scenario ‘Inheritance’, where Scenario A derives from Scenario B, which might, in turn, derive from another Scenario, C. For example, a ‘parent’ scenario might describe a water allocation regime, while multiple derived ‘child’ scenarios describe alternate demand patterns.
- Enumeration of Scenario Aspects, where Scenarios A1, A2, and A3 provide alternate values for one collection of model parameters (eg climatic inputs) and another set of Scenarios (B1, B2, B3, B4) contribute different parameters (eg demand). In this way, a set of scenarios can be built up using two (or more) Aspects, with the system running all combinations of scenarios.
- Combining discrete scenarios with stochastic scenarios, where one or more parameters is enumerated many times according to some distribution.
These patterns aren’t supported by the Input Sets feature in Source: That’s where SourceRy comes in.
SourceRy
SourceRy is a collection of R modules that supports these types of scenario patterns for Source. SourceRy is designed to be run interactively in R or through the use of R scripts tailored to your situation. Although SourceRy doesn’t have a fancy graphical user interface, it is hoped that users can run the system without being R-experts, by modifying existing, example ‘Potions’.
At its core, SourceRy coordinates running multiple Source models, with varying parameters, using parallel processing. SourceRy also coordinates user defined post processing of results.
Using SourceRy, model runs can be described in terms of discrete parameters (eg ScalingFactor=1.1), sampled parameters (eg ScalingFactor=fn(mean,std)) and a combination of the two. The parameters can be anything that you can modify using the Functions feature of Source - so you can define your own parameters by defining and using new functions within the Source model.
Scenarios in SourceRy
A typical use of SourceRy is to define a number of discrete scenarios, based on one ‘Aspect’ of model parameters, and then run each scenario for a number of replicates, created by sampling parameters from another Aspect, according to some distribution. For example, the discrete Aspect might represent different demand scenarios, while parameters related to supply might be sampled stochastically, generating the replicates.
Describing Scenarios
Discrete Aspects can be captured in CSV files, with each column representing a Function/Parameter in the Source model and each row representing a realisation of the Aspect: a partial scenario.
Scenario,DemandScaling,AllocationScaling
1, 1.0, 1.0
2, 1.1, 0.9
3, 1.2, 0.9
Sampled Aspects are generated by defining an R function that accepts a sample size and returns a matrix of replicates for the Aspect, with each column again representing a Function/Parameter from the Source model and each row representing a complete replicate. The function has complete control over the sampling process, so parameters can be independent or correlated as necessary.
Dealing with the Outputs
You can quickly specify a very large number of Source runs using SourceRy, so managing the correspondingly large volume of model outputs is essential. SourceRy allows custom post-processing to be attached to the end of the simulation job to in order to generate representative outputs. Post processing is specified by providing an R function that calculates the required statistics from a single model run. SourceRy then accumulates and summarises these values across all runs.
As an example, the following figure was generated when running SourceRy over two aspects: one discrete aspect representing different possible demand levels and one stochastic aspect representing different possible inflow sequences to a simple water supply system. Applying the variable inflow to each discrete demand scenario results in a distribution of the output statistic: % of demand met over the course of the simulation. Each discrete scenario is represented as a box-plot of this distribution, for side-by-side comparison.
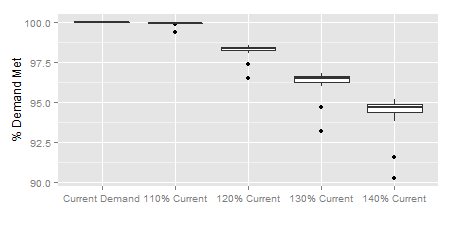
The full model outputs can also be retained.
Try a Potion
I like this ‘changes that matter’ approach to scenario management:
- The modeller gets to decide what is important to the scenario,
- It makes the scenario definitions explicit, rather than buried in a large model configuration, and
- It provides a lot of flexibility for constructing and combining scenarios.
At its core, SourceRy is about managing collections of model runs. Scenario management is an interpretation that comes through a particular SourceRy run. I’m capturing useful SourceRy scenario management patterns in a collection of Recipes (‘Potions’) intended for you to copy and modify for your own purposes.
SourceRy and the Potions are all available from the Flow Matters page on Github. The core modules and the potions are all licensed under the LGPLv3 license. I’m happy to answer questions about SourceRy and I’d certainly like to hear how you go with it.
Enjoy.